
Boost LLM Performance with Semantic Caching for Speed and Accuracy

Large Language Models (LLMs) face challenges in real-time applications, particularly in reducing latency in AI. The need for quick, accurate data retrieval from large datasets can cause delays, especially when processing complex queries at scale.
Semantic caching addresses these issues by focusing on data retrieval optimization and enhancing real-time data processing capabilities. By storing not just raw data but its meaning and context, semantic caching accelerates data retrieval speed and improves accuracy. This ensures that LLMs provide relevant, context-aware responses faster. Additionally, it reduces operational costs by minimizing repeated data processing, making LLMs more efficient and scalable for real-time applications.
What is Semantic Caching?
Semantic caching is a technique for data retrieval optimization that enhances real-time data processing through advanced data retrieval techniques and helps in reducing latency in AI. Instead of storing just raw data, semantic caching focuses on storing the meaning and context of data, allowing systems, like LLMs, to retrieve data based on its relationships and relevance to the current query.
This method ensures quicker responses by recognizing and retrieving contextually relevant information, thus improving real-time data processing and overall system efficiency while reducing latency in AI.
How Semantic Caching Works with LLMs
Contextual Analysis:
LLMs analyze the meaning and context of input queries, going beyond simple keyword matching. This enhances both data retrieval optimization and real-time data processing, enabling models to interpret complex queries more accurately. Advanced data retrieval techniques allow LLMs to understand and prioritize the most relevant data for specific queries.
Cache Storage:
Semantic caches store relationships between data points, not just raw data. When processing a query, contextually relevant data is retrieved rapidly, ensuring efficient real-time data processing and contributing to AI Integration for businesses by speeding up business processes.
Dynamic Updates:
As new data becomes available, the semantic cache updates to ensure relevance. This adaptability supports real-time data processing and ensures that LLMs can continue to deliver the most accurate responses while reducing latency in AI and supporting scalable AI solutions.
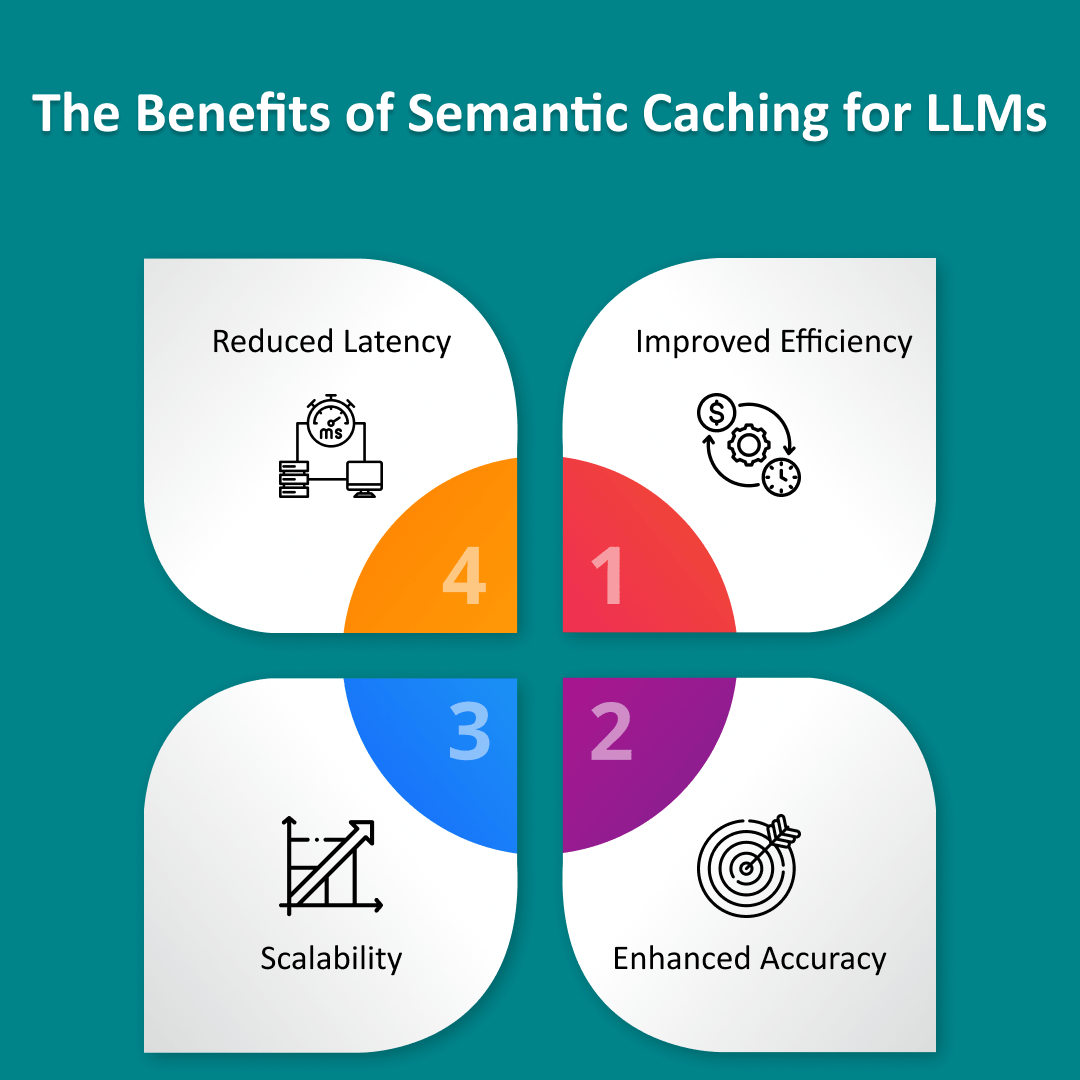
The Benefits of Semantic Caching for LLMs

Improved Efficiency: Semantic caching enhances efficiency by reducing redundant data processing. Cached data allows LLMs to bypass recalculating results, lowering computational load and improving performance.
Enhanced Accuracy: By focusing on context, semantic caching provides relevant responses to complex queries, using advanced data retrieval techniques to access the best matches.
Scalability: With reduced data retrieval time and reducing latency in AI, semantic caching supports systems that can scale easily, handling higher query volumes without slowing down, making it a critical component of scalable AI solutions.
Reduced Latency: Faster data retrieval boosts real-time data processing, critical for applications like chatbots and virtual assistants, which are key tools in AI Integration for businesses and help drive business optimization while reducing operational costs with AI.
Key Use Cases for Semantic Caching in LLMs
Customer Support:
Enables faster responses by recalling past interactions, reducing processing delays in real-time data processing.
Personalized Content Recommendations:
By storing user preferences, semantic caching enables faster, more relevant content recommendations, improving real-time data processing and making the platform's recommendations more adaptable and scalable AI solutions.
Knowledge Management:
Speeds up access to relevant data, enhancing real-time decision-making using advanced data retrieval techniques.
Natural Language Interfaces:
Maintaining conversation context helps voice assistants and chatbots provide smoother, faster responses, crucial for real-time data processing and reducing latency in AI, ensuring these systems are scalable AI solutions
Future of Semantic Caching in LLMs
- AI and LLM Advancements: Enhanced AI and LLM technologies will boost semantic caching for faster and more accurate real-time data retrieval, driving even greater AI Integration for businesses.
- Generative AI: Generative AI will improve caching by better contextualizing data for applications like chatbots.
- Advanced NLP Models: NLP advancements will refine the accuracy of semantic caching for more precise responses.
- Cloud Integration: Cloud-based semantic caching will enable faster, global data retrieval with better scalability.
- Long-Term Impact: Evolving LLMs and AI will make semantic caching essential for improving real-time system performance.
End Note
Semantic caching plays a pivotal role in optimizing LLM performance through data retrieval optimization and real-time data processing. By storing the context and meaning of data rather than just raw content, it boosts speed, accuracy, and scalability, making real-time applications more effective and responsive. As part of AI-driven business optimization, it provides businesses with the tools needed to streamline operations, reduce latency, and enhance system performance.
At Seaflux, we are deeply committed to advancing AI and Machine Learning solutions to drive business success globally. If you have questions or would like to explore how Semantic Caching can enhance your LLM applications, feel free to schedule a meeting with us. We're eager to discuss how we can integrate innovative AI technologies to optimize your system performance and efficiency.

Krunal Bhimani
Business Development Executive
Claim Your No-Cost Consultation!
Let's Connect

USA
4308 Meadowridge Drive Charlotte, NC 28226
INDIA
B-405, Navratna Corporate Park, Ambli Road, Ahmedabad, 380058
Company
Resources
Services

